
Хранилища Данных
Хранилище данных (аналитическое хранилище данных) - комплексная система для централизованного хранения, обработки и анализа большого объема данных, что позволяет организациям принимать обоснованные решения на основе данных (data-driven подход).
Базовая архитектура хранилищ данных
Если рассмотреть самую упрощенную архитектуру DWH, она будет содержать несколько компонентов:
- Системы источники данных
- транзакционные базы данных (например, база данных CRM-системы)
- приложения и системы, отправляющие данные с помощью программных интерфейсов (API) (например, API рекламных кабинетов: Яндекс.Метрика и т.п.)
- внешние открытые данные (пример: данные о курсе валют с открытого ресурса, забираемые парсингом или через API)
- файлы и документы (пример: папки с excel файлами в google drive или таблицы google sheets)
Источников данных может быть огромное множество. Чтобы эти данные попали в аналитическое хранилище, нужно построить data pipeline (поток данных). Можно провести аналогию с трубопроводом:
ключи и подземные источники ➔ строим трубопровод, отчистительные сооружения ➔ вода попадает потребителям
Тоже самое с данными, где ключи воды - источники данных. чтобы данные попали из источников в DWH нужны папйплайны (трубы) и механизмы выгрузки/загрузки/трансформации данных.
- Потоки данных (ETL/ELT)
ETL-процесс - процесс извлечения (extract), трансформации и преобразования (transform), загрузки (load) данных из системы источника в DWH. Более детально про подходы ETL/ELT и инструменты будет расписано в разделе ETL/ELT (Batch).
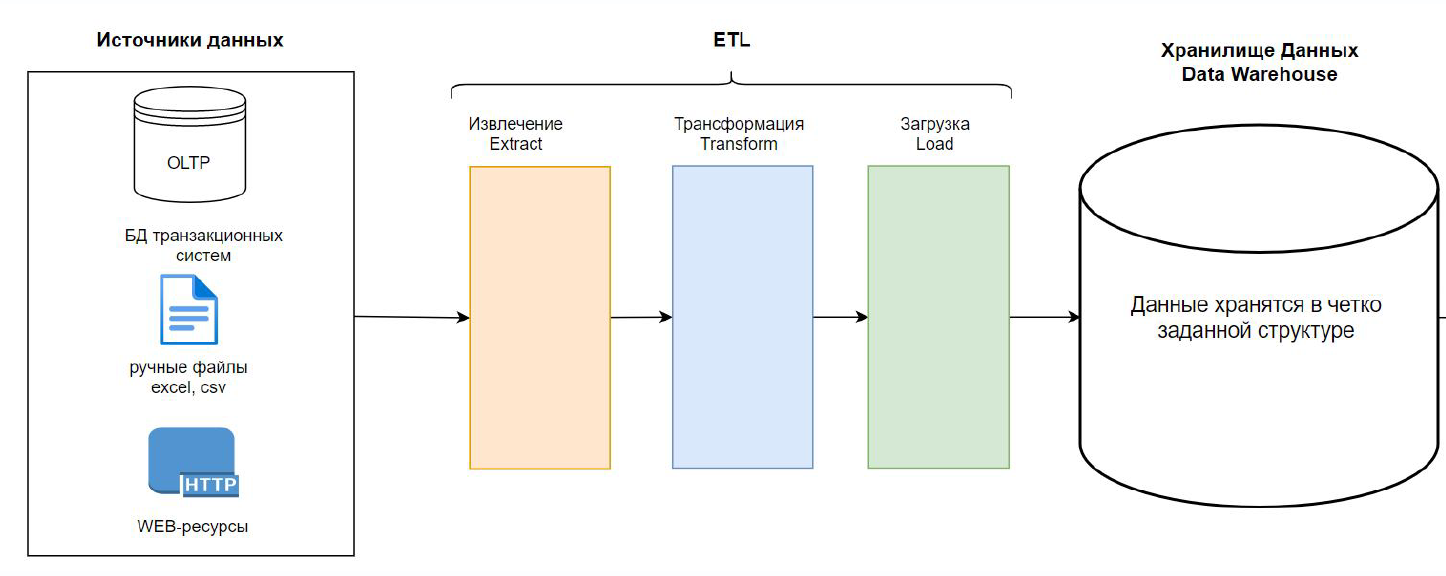
- Хранение данных
Хранилище данных включает ключевой компонент - само хранилище. В качестве хранилища могут использоваться различные аналитические базы данных и платформы для хранения данных. Например, Greenplum, ClickHouse, Snowflake, Amazon Redshift, Google BigQuery и др. Решение для хранения данных выполняет несколько функций:
- обеспечение надежного хранения большого объема данных
- предоставление доступа к данным на чтение/редактирование/удаление/вставку согласно ролевой модели и правам доступа пользователей
- обеспечение вычислительных ресурсов и возможностей для аналитики над данными
В хранилищах данные принято хранить на разных слоях (layers). В самом базовом сценарии обычно выдаляют 3 слоя:
- raw layer - необработанные данные, которые попали из источника
- core layer - слой обработанных данных, стандартизированных для хранения внутри сущностей хранилища
- business layer - подготовленные данные для отчетности или более детальной аналитики пользователями, витрины данных (data marts)
На практике каждая компания сама выбирает конфигурацию хранилища и слоев данных, которая подходит под требования и ключевые задачи конкретного бизнеса.
- BI-решения
Слой BI необходим для визуального представления результатов анализа, проведенного на основе данных из хранилища, и донесения этих результатов до бизнес-пользователей. Бизнесу нужны оцифрованные метрики в удобных для принятия решений формах: интерактивных отчетах (дашбордах), информативных визуальных графиках или презентациях от аналитиков, других формах отчетов (например, сообщениях в мессенджеры с ключевой информацией о метриках). Для реализации этих задач в архитектуру хранилища данных закладывают использование BI-инструментов, таких как Tableau, Power BI, Apache Superset, Datalens и других. Все BI-инструменты имеют функционал подключения к хранилищу данных, что позволяет удобно и быстро использовать данные из хранилища для построения аналитической отчетности.
Разнообразие архитектур хранилищ данных
Существует разные подходы к пострению хранилищ данных. Это обусловлено множеством факторов:
- различные форматы данных для хранения и обработки (структурированные и неструктурированные)
- разные задачи анализа данных (описательная BI-отчетность и/или обучение ML-моделей в разных областях CV, NLP)
- разные ресурсы, масштабы, корпоративные подходы и экспертиза компаний, внедряющих аналитические хранилища в свой бизнес
Исходя из этих факторов есть разные архитектурные подходы хранилищ данных
Data Warehouse
Это централизованное хранилище, предназначенное для хранения и анализа в большей степени структурированных данных. Оно оптимизировано для выполнения сложных аналитических запросов на языке SQL и построения BI-отчетности для бизнес-пользователей.
Примеры: Snowflake, Amazon Redshift, Google BigQuery, Greenplum, ClickHouse
Ресурсы:
- Архитектура хранилищ данных
- Что такое Data Warehouse и зачем оно бизнесу
- Как Data Warehouse помогает экономить бизнесу
- Как писать оптимальный код в Greenplum
Data Lake
Data Lake или Озеро Данных предназначено для хранения в большей степени неструктурированных данных. Данные хранятся в виде файлов. В озере данных можно хранить разные форматы файлов: аудио, картинки, видео, текстовые файлы, файлы структурированных данных, json и др.
В основном Озеро данных строится на основе S3-совместимых хранилищ (объектных хранилищ). Внутри хранилища создаются бакеты (buckets), каждый бакет имеет уникальное название. Внутри бакетов хранятся уже файлы. Аналогию хранилища данных упрощенно можно провести с папкой на компьютере, но есть важное отличие - объектные хранилища не поддерживают иерархическую структуру, т.е. нельзя создать бакет внутри другого бакета.
Еще один из больших плюсов Озер Данных: низкая стоимость хранилища по сравнению с решениями для Data Warehouse
Примеры: Amazon S3, Yandex Object Storage, Azure Data Lake Storage, Hadoop Distributed File System (HDFS)
Ресурсы:
- Что такое озера данных и почему в них дешевле хранить big data
- Чем озеро данных отличается от базы и зачем оно нужно аналитикам
- Data Lake в MTC
- What is Data Lake
- What is Amazon S3
- Как работает S3 и Yandex Object Storage
Data Lakehouse
Data Lakehouse - это гибридная архитектура, которая объединяет лучшие черты озер данных и хранилищ данных. Она обеспечивает гибкость и масштабируемость озер данных с возможностями управления данными, характерными для хранилищ данных в DWH. Плюс такой архитектуры в том, что она предусматривает как более дешевое хранение неструктурированных данных в Data Lake (также можно использовать для холодного хранения структурированных данных), так и все преимущества DWH для работы со структурированными данными в виде таблиц.
Примеры: Databricks Lakehouse, Delta Lake, Apache Hudi
Ресурсы:
- DWH + Data Lake или что такое LakeHouse
- What is a Data Lakehouse & How does it Work?
- What Is a Data Lakehouse?
Data Mesh
Data Mesh — децентрализованная архитектура, которая распределяет управление данными между различными доменами или командами. Каждый домен отвечает за свои данные и предоставляет их другим доменам через стандартизированные интерфейсы.
Для Data Mesh технически могут использоваться одни и те же инструменты как для других архитектур, разница здесь больше в правилах управления хранилищем и децентрализованном подходе. Представьте компанию, в ней есть, например, отделы маркетинга, продаж и поддержки клиентов. У каждого из отделов есть свои бизнес-процессы и данные.
В подходе Data Warehouse выделялась бы одна централизованная команда DWH, которая работает с отделами компании как разными бизнес-заказчиками. В Data Mesh каждый отдел компании имеет свои собственные ресурсы для управления своими данными для аналитики и является ответственным за свой бизнес-домен данных. А команда хранилища предоставляет в таком случае только работающее техническое решение для самостоятельного решения задач бизнес-доменами. Однако в децентрализованном подходе необходимо фиксировать единые правила и подходы для работы с данными - Data Governance и Data Management, без этого каждый бизнес-домен будет вслепую работать в своей зоне и не видеть общих подходов по работе с данными и инструментами.
Ресурсы:
Data Fabric
Data Fabric — это архитектура, которая интегрирует различные источники данных, системы хранения и аналитические инструменты в единую сеть. Она обеспечивает гибкость и масштабируемость для управления данными в реальном времени.
Ресурсы:
- Data Fabric — основы концепций и ключевые различия с Data Mesh и Data Lake
- Облачный конвейер аналитики Big Data: что такое Data Fabric
- What is Data Fabric
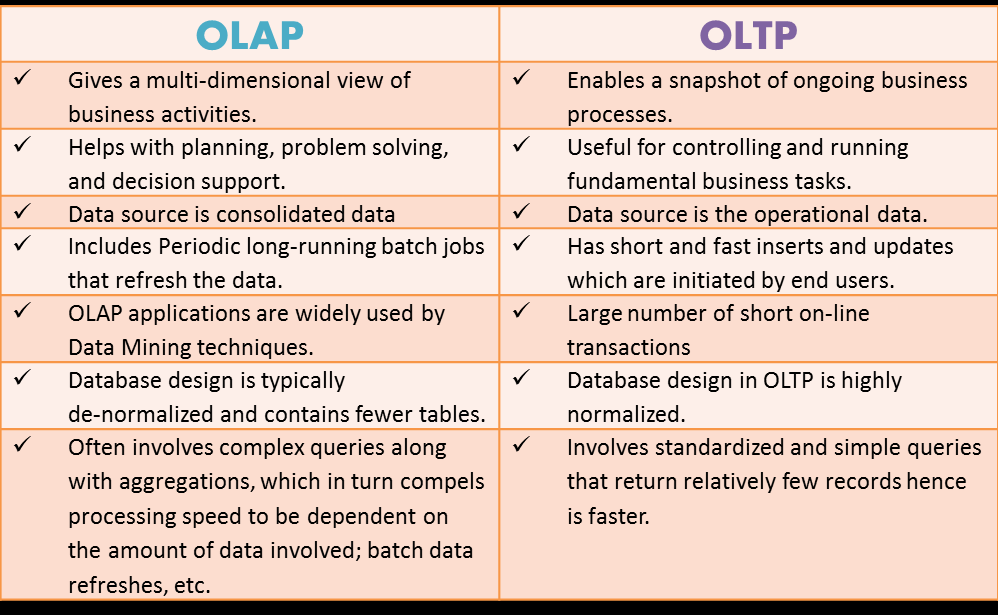
OLAP vs OLTP системы или почему База данных != Хранилище данных
OLAP (online analytical processing) - аналитические хранилища данных, про которые речь шла на этой странице выше. Их задача: хранить и обрабатывать большие объемы данных для аналитических задач бизнеса.
OLTP (online transactional processing) - транзакционные системы баз данных. Задача таких систем: фиксация и хранение данных для обеспечения операционной деятельности компании.
Ресурсы: